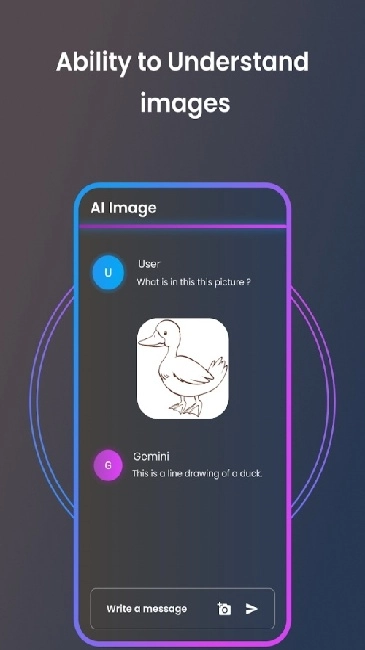
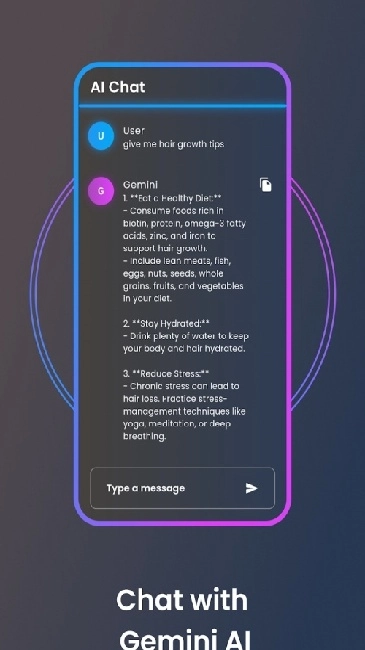
应用简介
这款由前沿人工智能技术支撑的智能交互工具,融合了卓越的语言推理能力与多模态生成技术。其背后的AI模型不仅在信息分析与逻辑识别方面表现突出,还能灵活适配商业预测、数据研判、内容创作等各类复杂场景。该工具可根据用户输入的文本内容,生成契合语境的视频或图像内容,有效提升创意输出的效率。此外,它还搭载了全新的视频生成模型Veo3,进一步拓展了从图文到视频的转换能力,适用于内容营销、教育培训、媒体制作等多个领域的应用需求。
温馨提示:在启动gemini之前,需要先安装谷歌三件套方可正常使用。
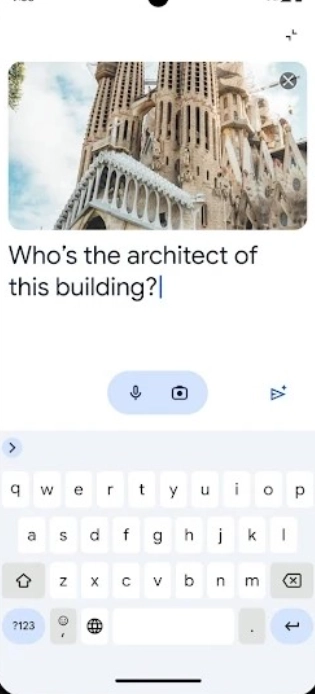
文本使用
用户能够在交互界面的输入区域直接输入问题、指令或者任务说明,比如粘贴一篇论文后补充“提炼核心观点”的要求,又或者提供完整的设定来让模型创作科幻小说,描述时要尽量清晰、详细,这样才能提高模型回应的精准度。
图片或音频分析
在操作界面找到上传标识并点击,即可从本地设备中挑选需要的文件进行上传。上传图片后,能够添加诸如“对图中人物的动作展开解析”之类的说明;上传音频后,则可以提出“分析语调与情绪的变化情况”等要求。系统具备多模态处理能力,能够实现图文、音音之间的协同分析。
获取结果
当你完成请求提交后,系统会在较短时间内给出对应的反馈内容,这些内容可能以文字概述、程序代码、数据解析等多种形式呈现。要是第一次得到的结果没有满足你的需求,你可以对输入的内容进行调整,或者补充相关的背景信息,不断完善你的指令,以便最终得到你想要的回答。
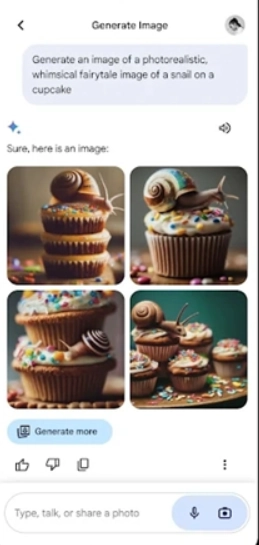
它可兼容文字、图片、音频等多种输入形态,能同步解析这些不同形式的信息,让交互过程更具弹性。
在复杂领域能保持稳定发挥,可协助文献分析与知识点解读,很适合用于深度学习。
拥有文本优化的能力,可增强内容的表达效果,无论是写作工作还是编辑任务都能够胜任。
会依据使用反馈持续优化回答的风格与内容,给出更契合用户习惯的建议。
能够产出各类编程语言的代码,同时也可以帮助对程序进行修复与优化。
它能够助力长篇文字的生成与润色,无论是学术论文撰写、故事创作,还是内容规划工作,都能发挥作用。
在学术研究的深度剖析领域具备扎实能力,可助力梳理晦涩的专业文献内涵,也能为探索新的研究路径提供建设性思路。
它能融合图像、文字、语音等多种类型的信息输入,对这些不同形式的内容进行识别与分析处理,从而能够适配更为广泛的实际使用场景。
上手容易却不失全面性,无论是日常学习、职场办公还是创意构思,都能从中找到适配的使用方式。
兼顾性能与安全,隐私保护机制完善,使用更安心。
能提供持续进化的服务体验,对话越多,反馈越准。
作为谷歌出品的AI,系统稳定可靠,品质有保障。
应用信息
最新更新应用换一换
spring弹簧相机
拍照美化 / 22.08MB
2026-04-22 更新
snapseed软件安装
拍照美化 / 28.13MB
2026-04-22 更新
句容人社
便捷生活 / 31.51MB
2026-04-22 更新
降温助手
办公学习 / 9.88MB
2026-04-22 更新
热门专题推荐更多
热门应用榜
一起来玩儿更多