2026-01-13 02:53:21|kindsoft |来源:kindsoft
今年年初的CES展会上,AMD推出了面向AI PC领域的高算力移动平台产品——AMD锐龙AI Max+系列处理器。该系列基于AMD Zen5架构打造,最引人注目的特性在于集成了多达40个RDNA3.5架构的图形计算单元,配备了带宽高达256GB/s的超高带宽内存接口,此外还内置了具备50TOPS算力的XDNA2架构NPU。
了解AI的朋友都知道,当前AI应用硬件层面的主要瓶颈就在于GPU与内存,无论是Stable Diffusion的文生图、图生图、文生视频等应用,还是围绕各种大模型的智能体类应用,只要涉及到本地化部署和使用,主要瓶颈就是GPU和内存。
锐龙AI Max+就瞄准了这两大痛点,通过高算力图形计算单元以及高容量、高带宽内存方案,让AI PC、迷你电脑也具备了堪比台式机的AI算力水平。
因此,锐龙AI Max+平台堪称当前性能最强、AI算力最为彪悍的移动级处理器。
今天我们拿到的是搭载AMD锐龙AI Max+ 395处理器的极摩客EVO-X2迷你电脑,它的定位是“Mini AI工作站”。

作为当前少数搭载AMD锐龙AI Max+ 395处理器的迷你电脑,极摩客EVO-X2桌面AI超算中心在AI应用方面究竟会有怎样的表现?通过本篇评测,我们来一探究竟。
·硬件配置与性能表现
首先我们看看这款机器的配置与性能表现。
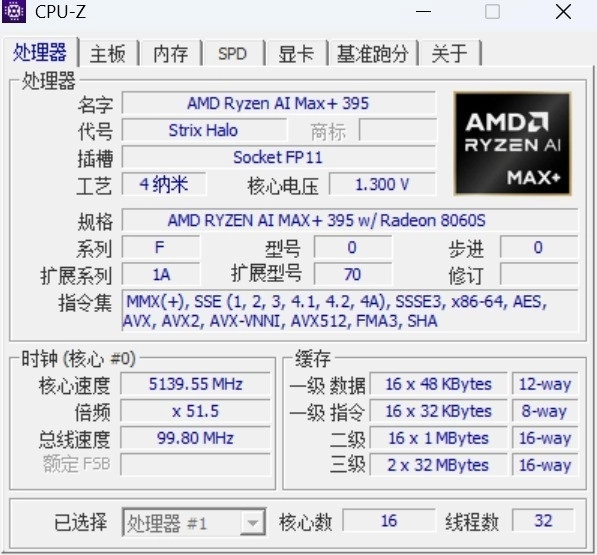
极摩客EVO-X2桌面AI超算中心搭载的AMD锐龙AI Max+ 395处理器,是锐龙AI Max+系列的顶配型号,原生16颗超大核心32线程设计,最高加速频率5.1GHz,总缓存高达80MB,NPU峰值AI算力为50TOPS,cTDP为45-120W,集成40个图形核心的Radeon 8060S iGPU。
【CPU单核/多核性能】
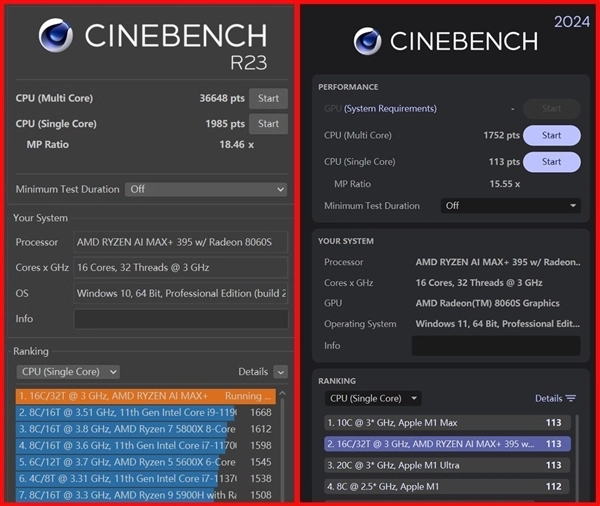
参考CINEBENCH R23和2024测试,锐龙AI Max+ 395处理器在R23测试标准下,单核得分1985,多核得分36648;2024标准下单核得分113,多核得分1752,整体性能表现非常出色,甚至可以探到移动端HX级别处理器的性能水准。因此锐龙AI Max+ 395并非“AI偏科生”,而是有着极其扎实的单核和多核性能实力。
【CPU功耗释放】
得益于极摩客EVO-X2桌面AI超算中心较大体积带来的内部空间,AIDA 64 FPU CPU单烤机实测这颗处理器的长时稳定功耗释放可以保持在103W附近,平均核心温度99.1℃,3分钟以内的短时功耗释放甚至可以达到120W。
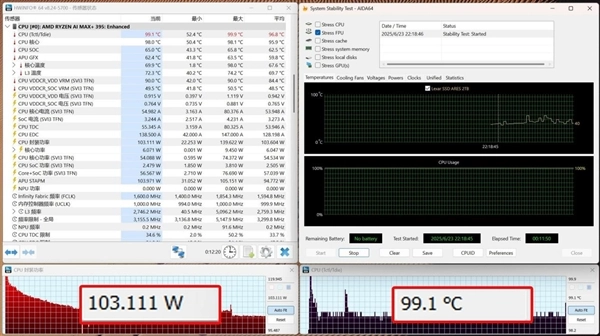
【内存读写性能】
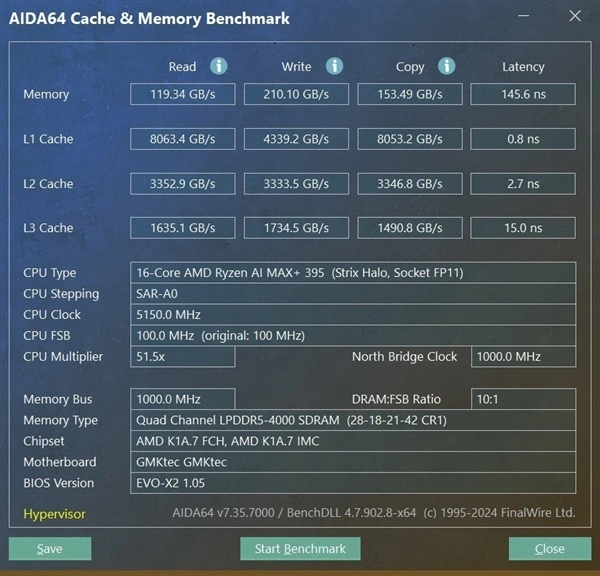
锐龙AI Max+ 395在设计时针对AI应用角度的这种特性,大幅提升了内存带宽,所以AIDA 64内存性能测试的结果极为出色。这款机器配备的双通道128GB LPDDR5x 8000高速内存读取速度高达119.34GB/s,写入速度高达210.1GB/s,拷贝速度高达153.49GB/s,速度极快。
【硬盘读写性能】
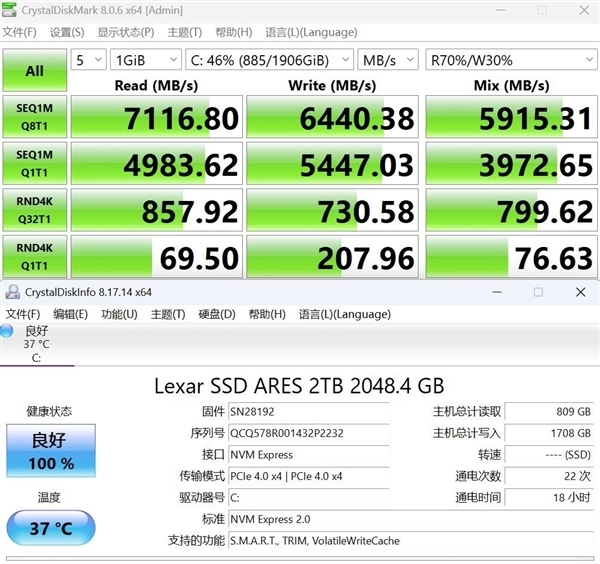
存储方面,极摩客EVO-X2桌面AI超算中心一步到位配备了2TB容量的雷克沙PCIe 4.0固态硬盘,实测顺序读取速度为7116.8MB/s,顺序写入速度为6440.38MB/s,4K随机读取速度为69.5MB/s,4K随机写入速度为207.96MB/s,达到了PCIe 4.0固态硬盘的高端性能水准。这非常有助于大参数量大语言模型的载入速度。
【GPU图形性能】
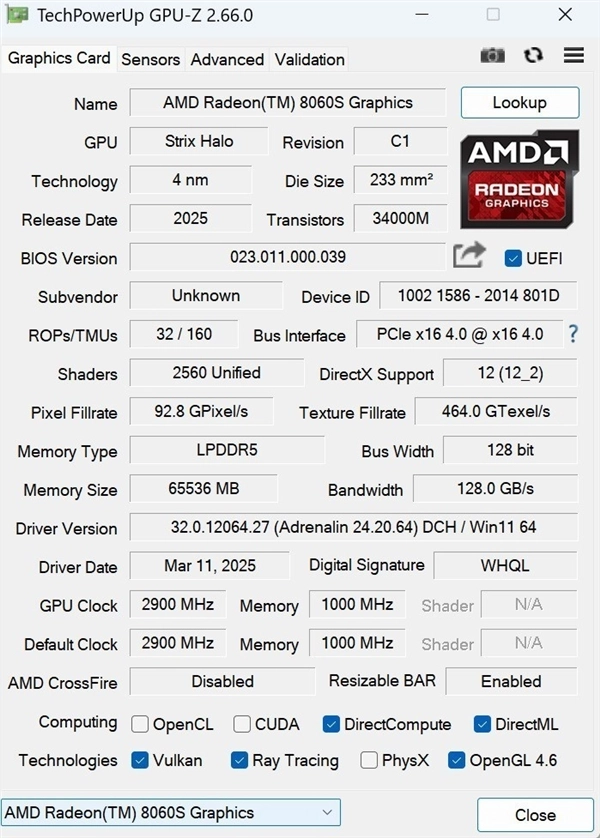
锐龙AI Max+ 395之所以能够胜任大参数量AI大模型的需求,很重要的原因在于它集成的Radeon 8060S iGPU,这颗GPU在集成显卡中可以说是超模的存在。它拥有2560个流处理器,64GB LPDDR5显存,128GB/s显存带宽,核心频率高达2900MHz,显存频率1000MHz,比当前任何一款集成显卡的性能都要强很多。
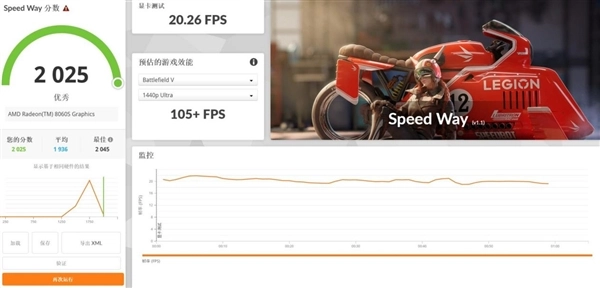
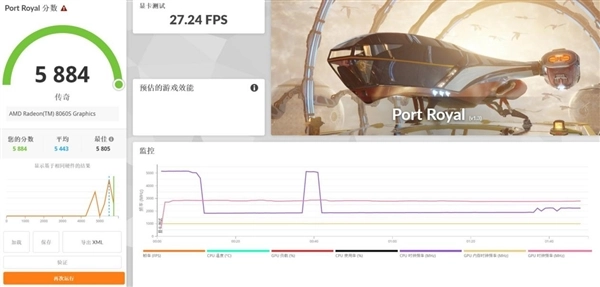
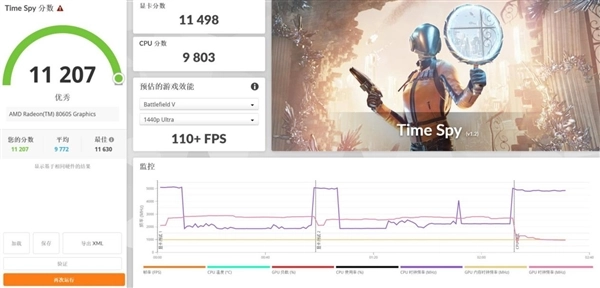
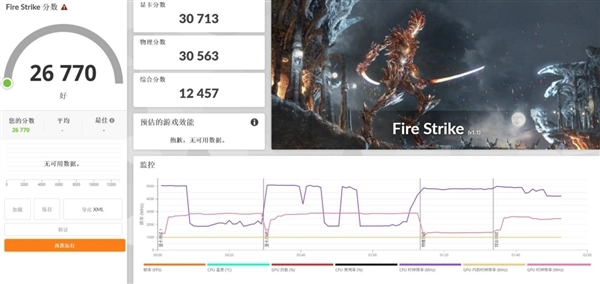
从3DMark的各项测试数据来看,Radeon 8060S集成显卡(iGPU)在Speed Way DX12项目中取得了2025分的成绩,这一表现显著领先于其他集成显卡;在Port Royal光追测试中,它的得分达到5884分,已接近RTX 4060独立显卡约5957分的水平;此外,Time Spy和Fire Strike图形测试得分分别为11498分与30713分。作为一款集成显卡,其理论图形性能不仅达到甚至超过了RTX 4060独显的水准,这样的表现确实令人惊喜。
·综合应用性能评估
CPU、内存、硬盘、GPU理论性能了解之后,我们来看看如此出色的综合性能能够在实际应用中获得怎样的体验?
【CPU应用性能】
首先是CPU相关的应用性能表现。
7-Zip压缩与解压缩测试中,锐龙AI Max+ 395处理器得益于16颗超大核心32线程设计,压缩速度达到了150617KB/s,解压缩速度达到了2063057KB/s,总评分高达177.76GIPS,是目前移动级处理器中T0级别的性能水准。
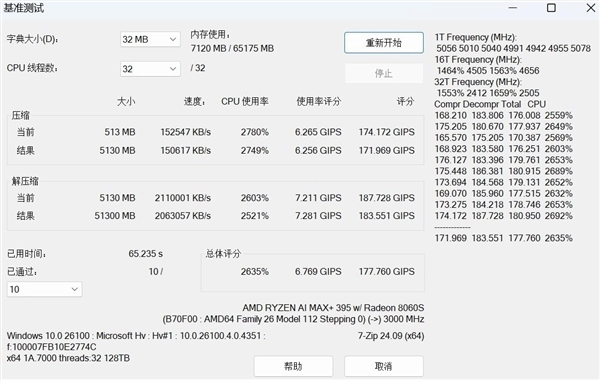
视频编码方面,x264 Benchmark实测编码2500帧的帧速率为77.31fps,完成时间为32秒,相对于HX系列的处理器要略慢一些。
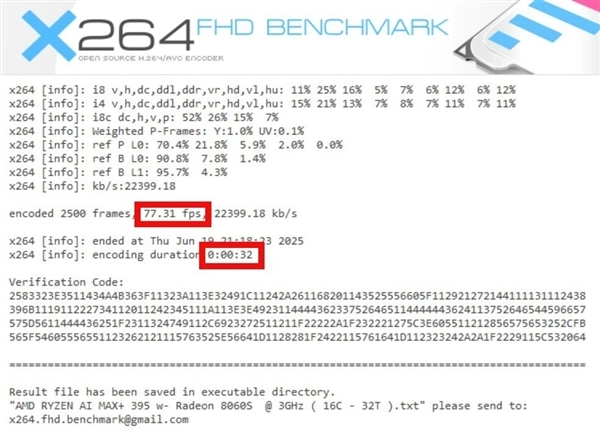
渲染方面,V-Ray Bencmark 1分钟采样率达到38813 vsamples;Corona Benchmark渲染速度达到了11248700Rays/sec,渲染用时仅43秒。
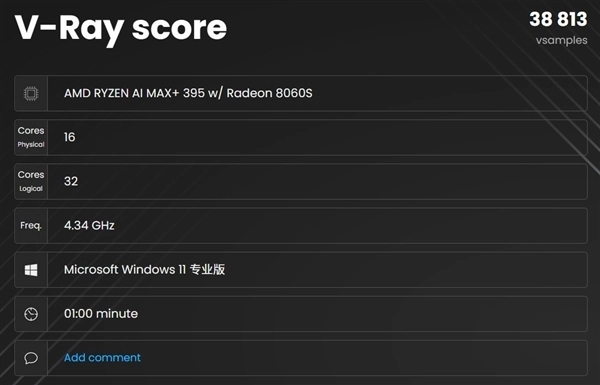
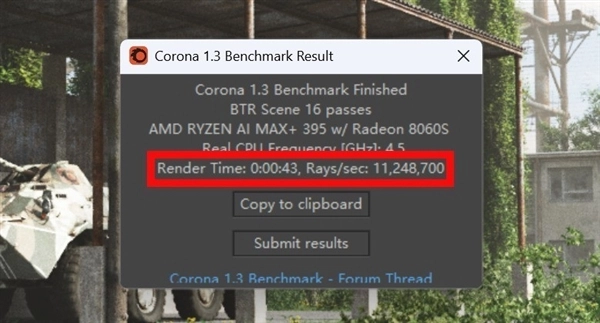
总体来说,锐龙AI Max+ 395处理器在压缩、解压缩以及物理渲染方面有着远高于其它移动端处理器的性能表现,而视频编码能力满足生产力需求也是不成问题的。
【GPU应用性能】
接下来再看看GPU相关的应用性能。
首先是V-Ray Benchmark的加速测试,1分钟渲染速度达到了1812 vpaths,在集成显卡中鹤立鸡群。
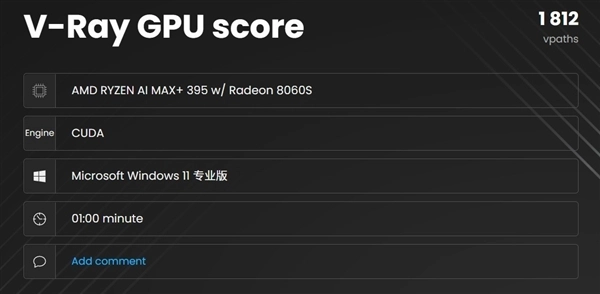
Blender benchmark的表现同样出色,monster、junkshop、classroom三项渲染采样率分别达到560.23、199.86以及252.34 samples/min,同样远超当前其它集成显卡的性能。

【综合应用性能】
最后看看综合应用性能。
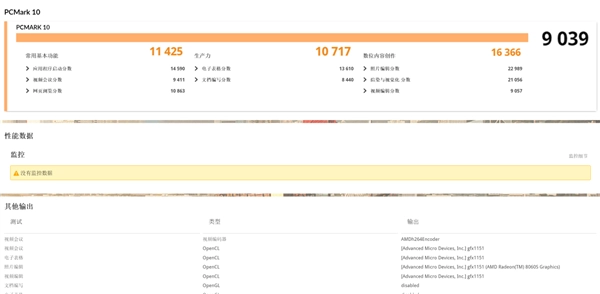
我们通过PCMark 10办公模式测试来评估生产力理论性能:在常用基本功能测试中,涵盖Web浏览、视频会议、应用程序启动等项目,得分达11425分,足以证明其完成基础办公任务毫无压力;生产力项目测试得分高达10717分,显示出在电子表格处理、文档工作方面具备出色性能;数位内容创作评分更是达到16366分,意味着它能高效胜任图片编辑、视频制作、图形渲染等工作;综合得分9039分,应对日常办公与娱乐应用完全不成问题。
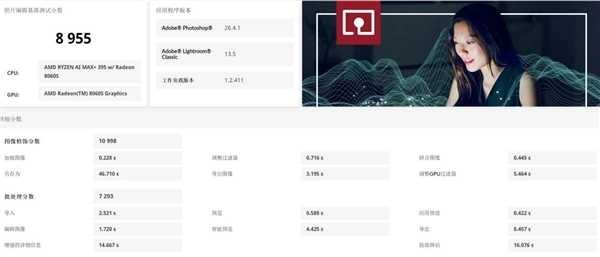
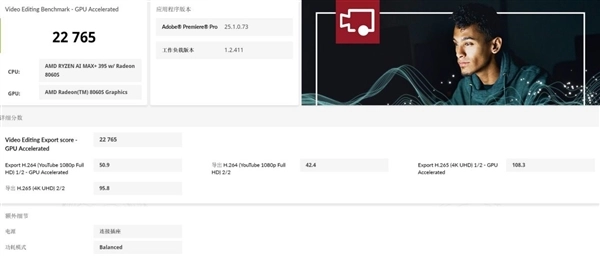
生产力应用性能我们参考UL Procyon的照片编辑和视频编辑测试,二者评分分别达到了8955和22765分,可以相当轻松地胜任RAW格式原片处理,并且在2K、4K视频剪辑上也能提供极为出色的性能支持。
·AI性能评估
搭载AMD锐龙AI Max+ 395处理器的极摩客EVO-X2售价为14999元,对于大众用户这个价格不便宜,但是如果将它与动辄数万、数十万元的AI一体机来做对比的话,这款机器可以说是目前成本相当低的AI学习、开发、应用平台,对初步上手AI的人群来说非常适合。
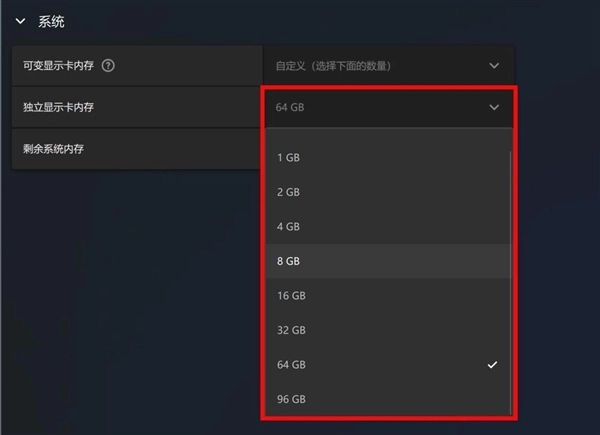
了解AI的朋友都知道,显存和内存在AI应用中非常重要,Radeon 8060S虽然图形性能极为出色,但其显存也不过就是6GB,应对AI大语言模型的应用需求有点捉襟见肘。不过通过AMD独特的统一内存技术,在AMD软件控制中心,我们可以将极摩客EVO-X2的128GB内存分配给集成显卡作显存,最高可以分配96GB,这样就可以承担起大参数量大语言模型的应用需求了。
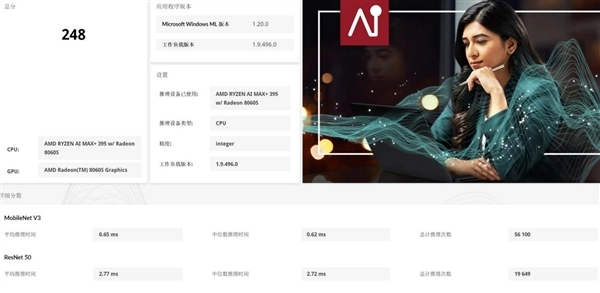
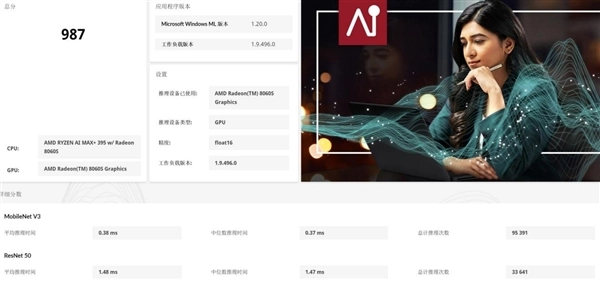
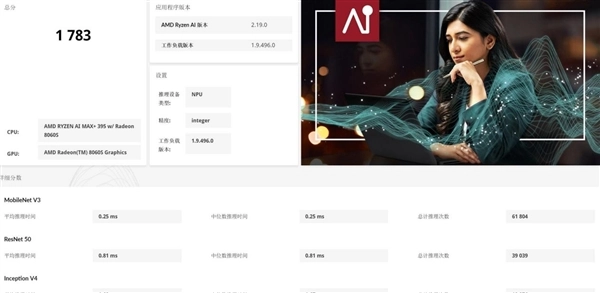
在开展AI应用测试前,我们先对锐龙AI Max+ 395处理器的CPU、GPU与NPU这三大AI计算单元的算力表现进行分析。依据UL Procyon的CPU Integer、GPU Float 16和NPU Integer测试,其三项评分依次为248分、987分和1783分。对比之前的锐龙8040系列处理器,锐龙AI Max+ 395处理器的CPU AI算力提升幅度较为有限,不过GPU和NPU的AI算力提升基本都达到了3倍以上!
理论性能了解之后,我们看看锐龙AI Max+ 395在实际AI应用中的表现。
首先使用UL Procyon对Phi-3.5 4B、Mistral 7B、Llama 3.1 8B和Llama 2 13B这四款主流大语言模型进行了测试,它们的生成速度依次为69.56 tokens/s、44.87 tokens/s、38.01 tokens/s和25.45 tokens/s,表现出相当快的处理效率。此外需要说明的是,像RTX 5060这类笔记本独立显卡,由于仅配备8GB显存,难以顺畅运行参数量较大的Llama 2模型;而Radeon 8060S不仅能成功驱动该模型,生成速度还能达到25.45 tokens/s,完全满足日常使用需求。在这种情况下,锐龙AI Max+ 395平台的独特优势便得到了充分体现。
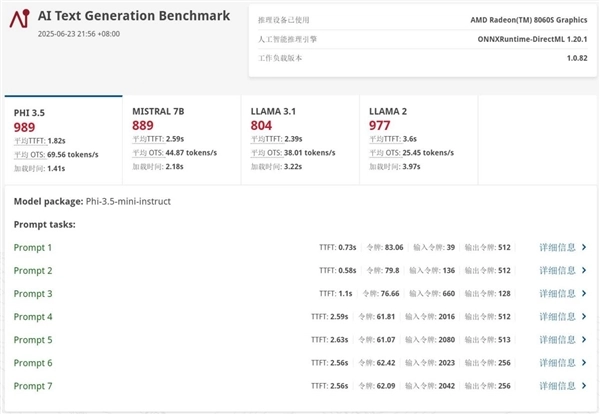
接下来我们通过LM Studio进行了15B及以下小参数量大语言模型和22B及以上大参数量大语言模型的测试。
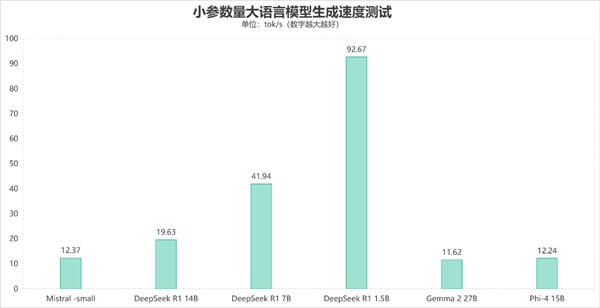
在各类小参数量稠密大模型的测试场景中,锐龙AI Max+ 395展现出了十分亮眼的表现。借助内存分配机制所带来的超大显存支持,即便面对BF16高精度规格的Mistral-small 24B与Gemma 2 27B这类大模型,其生成速度也分别达到了12.37 tokens/s和11.62 tokens/s,性能表现可圈可点。而针对性能要求更高的DeepSeek R1 14B、Phi-4 15B模型,它的生成速度也能稳定在19.63 tokens/s和12.24 tokens/s;在低精度模型测试中,DeepSeek R1 7B的生成速度更是高达41.94 tokens/s,DeepSeek R1 1.5B则达到了92.67 tokens/s。由此可见,在应对小参数量大模型时,无论面对的是高精度还是低精度版本,锐龙AI Max+ 395都能提供足够高效的生成速度。
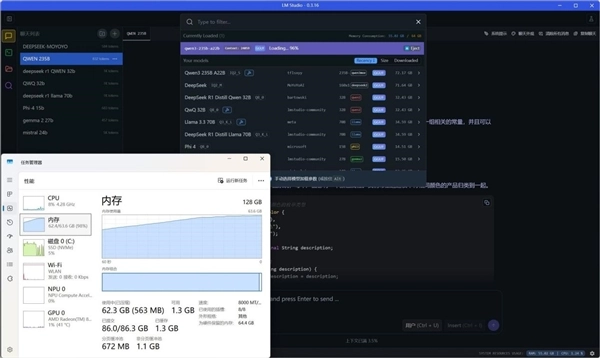
在面对大参数量大语言模型时,其实首要解决的问题不是能不能使用大模型,而是能不能正常加载大模型。就比如RTX 5060笔记本电脑GPU,虽然其性能比Radeon 8060S要强,但如果大模型参数量较大,前者大概率也过不了加载这一关,更别提进一步应用了。
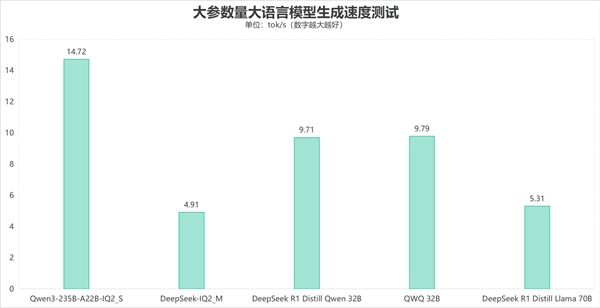
从下图可以看到,我们在加载Qwen3-235B-A22B-IQ2_S的MoE混合大模型时,内存峰值占用高达63.6GB,如果没有128GB超大内存支持的话,加载这一关就过不了。
在各类大参数量大语言模型的测试过程中,Qwen3-235B-A22B-IQ2_SMoE模型展现出亮眼的表现,其生成速度达到了14.72 tokens/s;另外,DeepSeek IQ2_M、DeepSeek R1 Distill Llama 70B这两款大参数量稠密模型不仅能够正常运行,生成速度还分别达到了4.91 tokens/s与5.31 tokens/s。至于Q4量化版本的DeepSeek R1 Qwen 32B蒸馏模型以及QWQ 32B大模型,它们的生成速度则分别可达到9.71 tokens/s和9.79 tokens/s。
这里还需要补充说明一点:Qwen3-235B-A22B-IQ2_S模型的参数量虽达235B,但它并非传统的稠密模型,而是MoE(混合专家)模型。通俗来讲,MoE模型的总参数量通常较大,不过以该模型为例,尽管总参数量为235B,实际运行时却仅调用22B的参数参与计算——模型名称中的“A22B”正是这一特性的标识,意味着运行时仅启用22B参数量,因此对硬件的负载压力会小得多。
也正是因为有着这种大参数、低算力特性,MoE模型或许会成为未来大模型发展的主流趋势。
反之,稠密模型每一次计算都会调用所有参数,这也就是为什么235B的Qwen3-235B-A22B-IQ2_S生成速度反而比DeepSeek R1 32B、QWQ 32B大模型要快的原因。
AI测试的最后一部分,我们使用了针对AMD锐龙平台打造的Amuse这款Stable Diffusion工具,它支持文生图、图生图、文生视频等应用,使用起来非常方便。
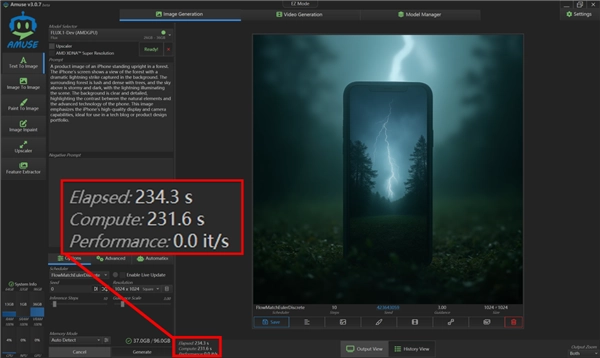
首先我们使用最近大半年非常火爆的FLUX.1-Dev模型进行了文生图测试,实测迭代10步,生成一张1024 x 1024超清图片用时234.3秒。这个表现虽然不如独显,但在集成显卡里,能顺利完成这一任务的此前没有,Radeon 8060S不仅顺利完成,而且效率也还不错,毕竟1024×1024规格的图片生成,在AI文生图应用中算是高负载任务了。
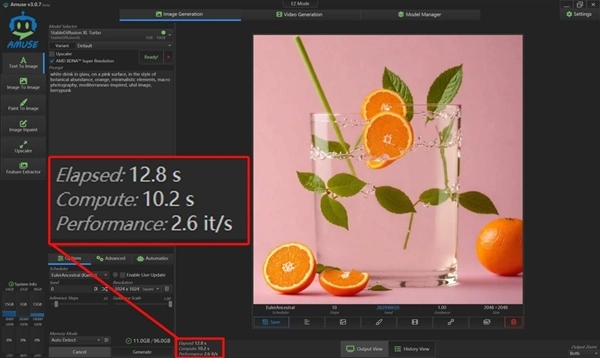
其次我们使用了Stable Diffusion XL Turbo模型,进行了2048x2048规格图片的生成。这款大模型整体精度要低一些,所以对硬件负载的压力不算太高。普通用户使用这类大模型进行文生图就足够了,没必要使用FLUX.1-Dev这种超高精度大模型。
可以看到,Stable Diffusion XL Turbo模型生成2048x2048规格图片耗时仅需12.8秒,每秒迭代次数也达到了2.6次。
总体来说,锐龙AI Max+ 395是非常不错的AI计算平台,配合大内存并通过AMD统一内存技术分配给显存之后,常规的AI应用基本没有太大压力,完全可以作为个人或者小型工作室、小型企业用户的AI终端设备。尤其相比动辄数万、数十万元的AI一体机来说,14999元的极摩客EVO-X2绝对是一个高性价比的解决方案。
同时,这类设备也非常适合AI初学者、初级AI开发者使用。首先,锐龙AI Max+ 395平台配合超大内存,完全可以在本地部署多样化的AI大模型,如70B、32B大语言模型,或者Flux、StableDiffusion等文生图、文生视频大模型。借助LMStudio、Comfy-UI等AI工具,轻松实现本地化的AI助手、个人知识库以及图片、视频创作平台的搭建。
其次,超大内存与显存为AI应用体验带来显著提升。例如,用户在实际使用中能够同时加载Stable Diffusion、Whisper与Llama这类混合式AI模型方案,借助AI来解决AI应用场景中的问题——比如让AI直接生成提示词,再通过SD工具完成图片与视频的创作。与此同时,锐龙AI Max+395平台还兼容ONNX、DirectML等多种技术框架,可完美适配Windows平台的部署与运行需求。因此,该平台也十分适合多模态AI应用场景,像图片放大、图像分割、语音识别、图像识别等任务都能高效处理,既能节约实验或验证阶段的成本,又能帮助开发者快速完成Demo或开源项目的开发工作。
其三,设备成本支出更低的同时,本地化部署带来的另一大好处就是使用成本几乎为零。用户无需额外支付Token费用,也不受网络质量影响。同时拥有更加可靠的用户隐私、数据安全,算法模型数据不容易外泄。
此外,锐龙AI Max+ 395的NPU也可以参与YOLO等适配模型的相关任务,分担负载,从而让多模态应用拥有最优的算力表现。
·游戏性能评估
锐龙AI Max+ 395集成的Radeon 8060S本身拥有相当不错的图形性能,因此对于游戏玩家来说也是不错的选择。所以性能测试的最后一部分,我们进行了四款热门游戏的测试。
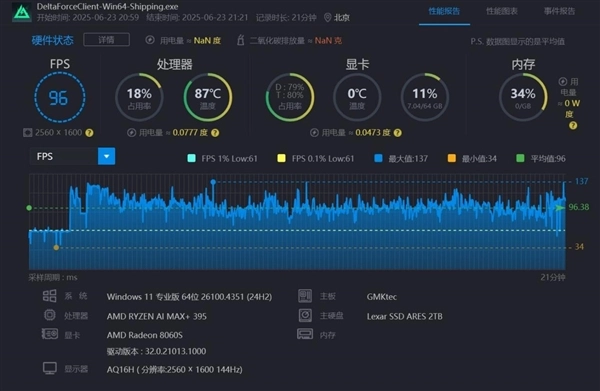
《三角洲行动》,极高画质(次高画质),2560x1600分辨率,平均帧率可以达到96fps,流畅运行无压力。
《荒野大镖客2》,中等画质,2560x1600分辨率,开启FSR,平均帧率可以达到89fps,运行非常流畅。
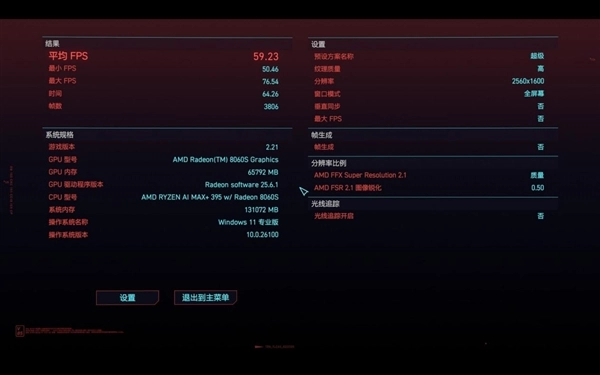
《赛博朋克2077》,超级画质,未开启光追,2560x1600分辨率,平均帧率可以达到59.23fps,接近60fps的表现已经远超当前其它集成显卡了。
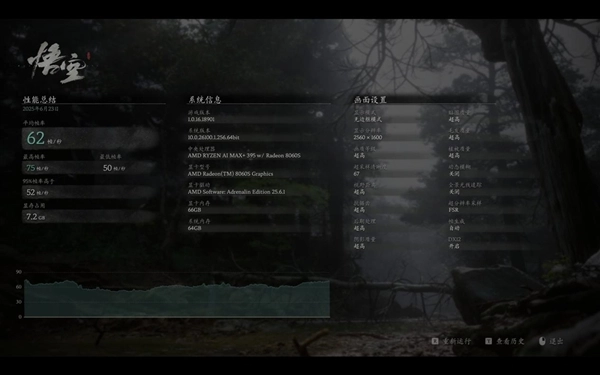
《黑神话:悟空》,超高画质(非影视级画质),2560x1600分辨率,平均帧率达到了62fps,可以流畅游玩。
可见极摩客EVO-X2不仅拥有出色的AI性能,同时还有着不错的游戏性能,再加上出色的生产力性能,这款产品可以说是相当能打的一款综合性迷你主机了。而且确实不负“桌面AI超算中心”之名!




·简约干练的外观设计
作为一款较大体积的迷你电脑,极摩客EVO-X2桌面AI超算中心在设计上还是很有看点的。这款机器整体采用了类似“夹心饼干”的设计方式,顶部和底部采用银色金属面板打造,中间采用黑色配色,从外观配色上就给人一种很极客的感觉。

这款机器的设计风格简约,卧放时正面的切角区域印有“GMKtec”的品牌LOGO,五边形切角设计打破了正方形机身“循规蹈矩”的感觉。正如其独特的配置一样,仿佛彰显着不拘一格、打破壁垒的产品语言。

这款机器支持卧放和立放,可以适应不同尺寸的办公空间。另外可以看到切角对应的区域设计有一枚三角形按键,它的作用是一键切换风扇的灯效模式。可以很方便的在常亮、呼吸等灯效模式中快速切换。

极摩客EVO-X2桌面AI超算中心有着非常出色的接口扩展能力,机身前端配有电源键和P-Mode性能模式切换快捷键。同时还配有标准的SD卡插槽,1个USB4接口,2个USB 3.2 Type-A接口以及3.5mm耳麦插孔。

机身背部接口就更加丰富了。包括安全锁孔,电源插孔,3.5mm耳麦插孔,RJ45以太网口,1个USB 3.2 Gen 2 Type-A接口,1个USB4接口,1个DP1.4视频端口,1个HDMI2.1视频端口以及2个USB2.0接口。

另外可以看到在接口区域下方,还设计有四个散热格栅。同时机身底部面板也开有大面积的散热孔,整体散热效率得到保障。

·评测总结
年初我在CES参加AMD发布会时,就对锐龙AI Max+ 395产生了极大兴趣。因为在整个行业里,锐龙AI Max+是颇为独特的存在,它从CPU的角度赋予了AI PC更加确切的定义,让移动端的AI处理器与传统移动端处理器产生了区隔。不过说实话,当时对于锐龙AI Max+的实际表现还是颇有疑问的,毕竟集成显卡跑出超越独立显卡的AI性能,在年初还是一件相当魔幻的事情。
不过在这次对锐龙AI Max+ 395处理器和极摩客EVO-X2桌面AI超算Mini工作站的深入测试中,此前的疑虑被彻底打破。MoE混合专家模型的出现,或许是未来锐龙AI Max+ 395这类处理器切入大参数量模型本地部署和应用的主要方式,而且实际效果真心不错。
此外,锐龙AI Max+ 395有着非常不错的生产力性能和游戏性能,对于迷你电脑、笔记本电脑来说也是相当靠谱的硬件解决方案。
而对于极摩客EVO-X2桌面AI超算中心这款产品来说,笔者个人认为它非常适合正在学习AI、研究AI、或者本地部署使用AI的工作室、小型企业用户选择,算得上是当前极低成本的高算力AI解决方案了。